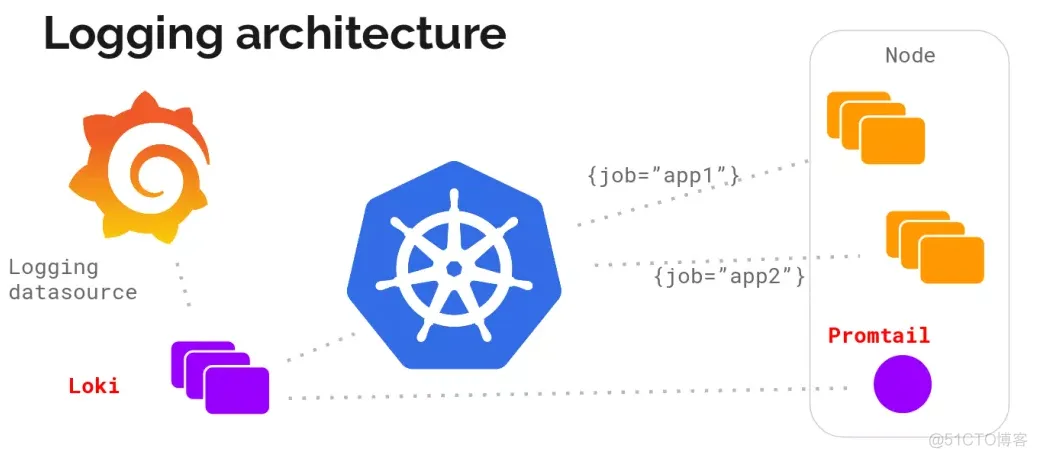
本文将介绍如何使用Loki + Promtail + Grafana完成日志的收集、展示、日志报警等功能,因为我也是刚接触两个月的时间,文章会逐步完善,通过这套体系我们完成了对多云环境下的日志收集,日志报警与日志的统一展示
首先,为什么不适用ELK?
现有的很多日志采集的方案都是采用全文检索对日志进行索引(如ELK方案),优点是功能丰富,允许复杂的操作。但是,这些方案往往规模复杂,资源占用高,操作苦难。很多功能往往用不上,大多数查询只关注一定时间范围和一些简单的参数(如host、service等),个人认为在当前云原生环境下,尤其是kubernetes已成为事实标准,基于指标的查询Loki架构要强于elk
组件介绍
- loki是主服务器,负责存储日志和处理查询。
- promtail是代理,负责收集日志并将其发送给 loki 。
- Grafana用于 UI 展示。
整体流程: promtail => loki <=> grafana
Promtail
promtail组件在整个架构中是日志的搬运工,我们不生产日志,我们只是日志的搬运工,使用daemanset部署在k8s中,通过k8s的api获取日志,并将获取到的日志源源不断的推送到Loki中去存储
关于promtail组件,基本没有做什么配置,属于是开箱即用,后面再做补充
Loki
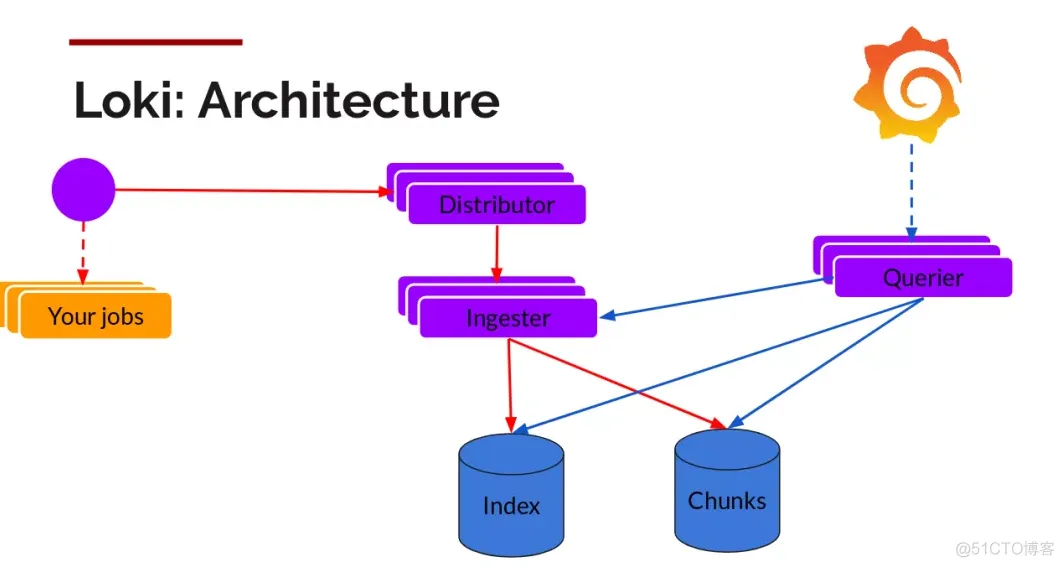
架构
读写
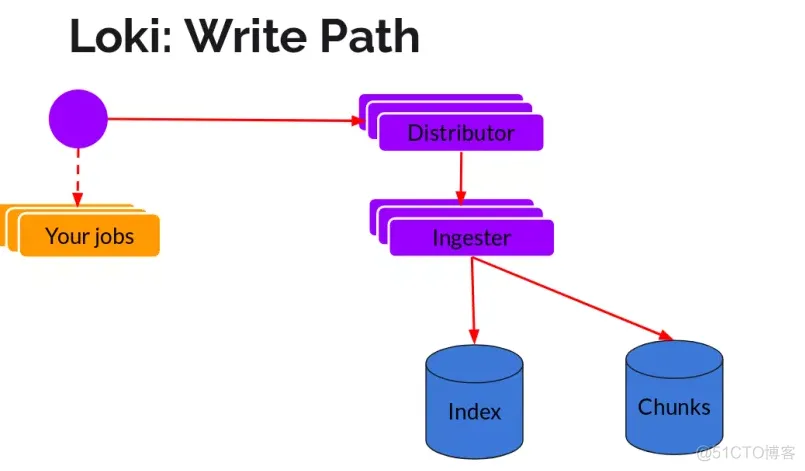
日志数据的写主要依托的是Distributor和Ingester两个组件,整体的流程如下
Distributor
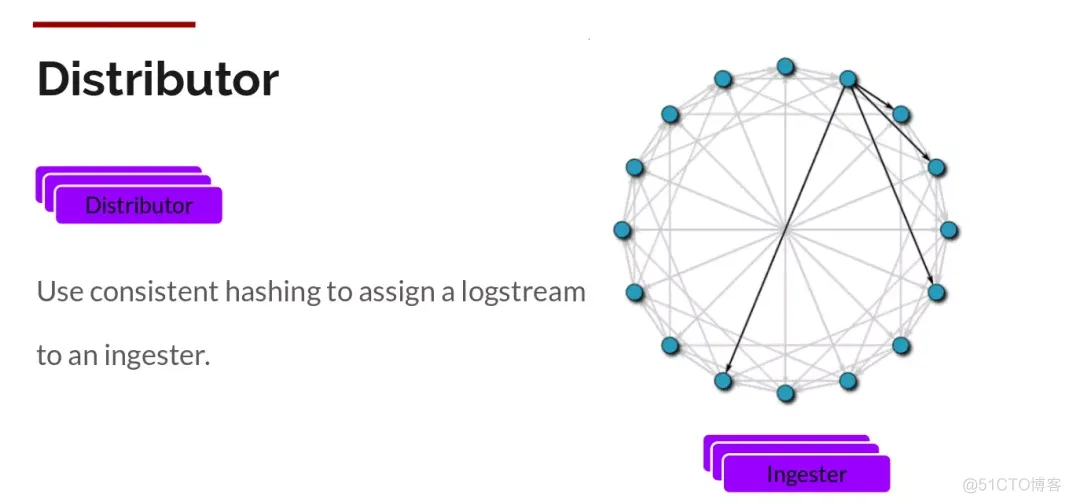
一旦promtail收集日志并将其发送给loki,Distributor就是第一个接收日志的组件。由于日志的写入量可能很大,所以不能在它们传入时将它们写入数据库。这会毁掉数据库。我们需要批处理和压缩数据。
Loki通过构建压缩数据块来实现这一点,方法是在日志进入时对其进行gzip操作,组件ingester是一个有状态的组件,负责构建和刷新chunck,当chunk达到一定的数量或者时间后,刷新到存储中去。每个流的日志对应一个ingester,当日志到达Distributor后,根据元数据和hash算法计算出应该到哪个ingester上面
Ingester
ingester接收到日志并开始构建chunk
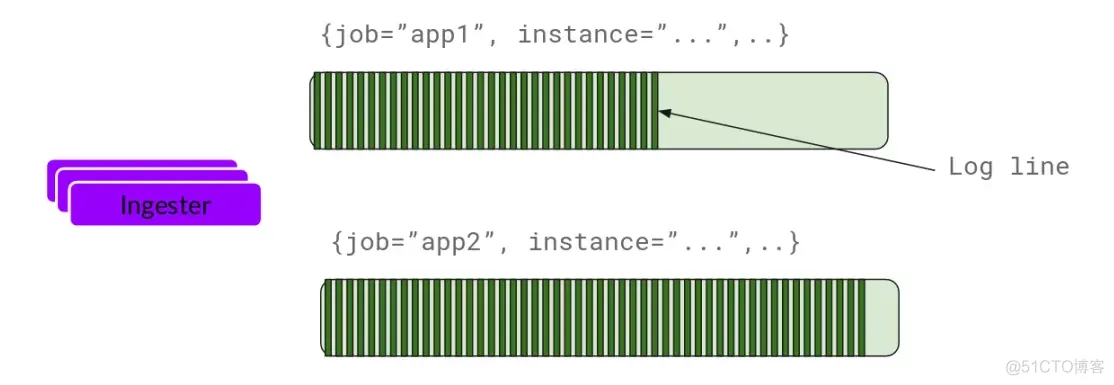
基本上就是将日志进行压缩并附加到chunk上面。一旦chunk“填满”(数据达到一定数量或者过了一定期限),ingester将其刷新到数据库。我们对块和索引使用单独的数据库,因为它们存储的数据类型不同

刷新一个chunk之后,ingester然后创建一个新的空chunk并将新条目添加到该chunk中。
Querier
读取就非常简单了,由Querier负责给定一个时间范围和标签选择器,Querier查看索引以确定哪些块匹配,并通过greps将结果显示出来。它还从Ingester获取尚未刷新的最新数据。
对于每个查询,一个查询器将为您显示所有相关日志。实现了查询并行化,提供分布式grep,使即使是大型查询也是足够的。
Grafana
grafana组件就非常简单了,添加数据源=> 查询
添加数据源
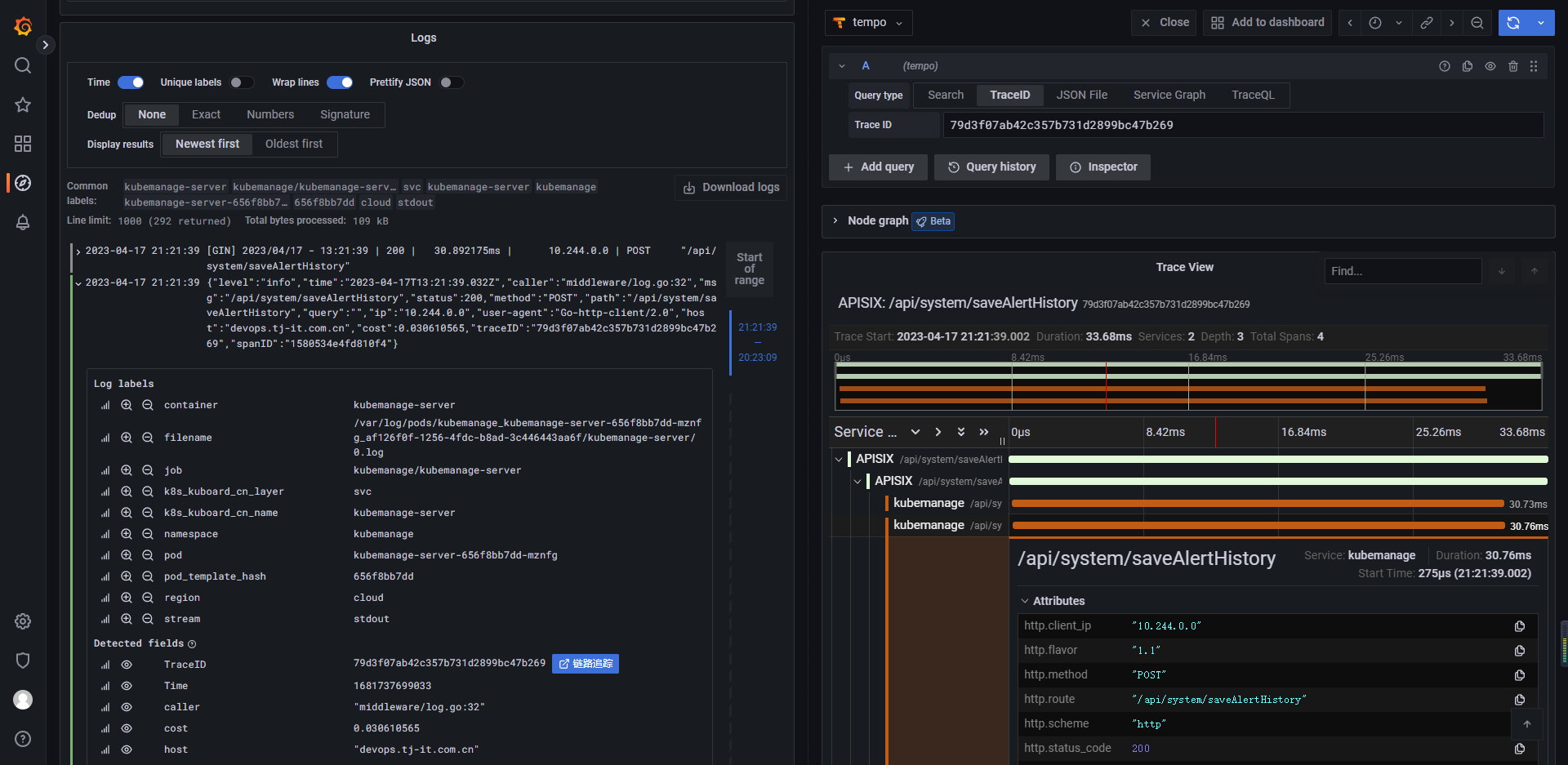
日志与链路追踪的联动
我们知道grafana全家桶是有链路追踪tempo的,通过正则可以把日志条目中的tracdID提取出来,并交给tempo组件实现日志与链路追踪的联动,前提是日志中携带traceID
数据源配置正则匹配
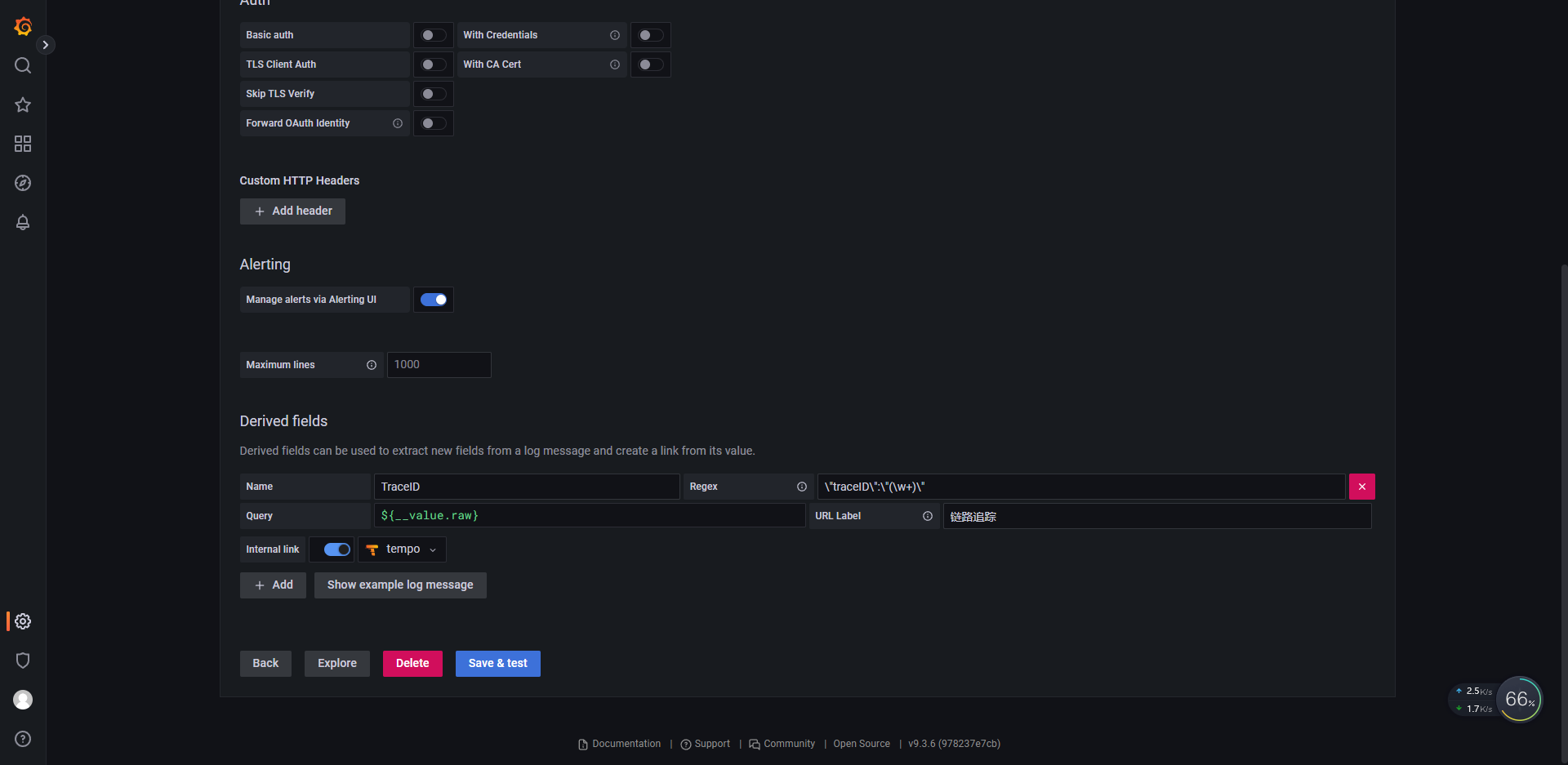
实现联动