
本文介绍了如何在消费级显卡上使用SGLang框架推理千问最新发布Qwen3.5-9B版本的小模型与BAAI/bge-reranker-large跟BAAI/bge-m3,无坑版本,可直接运行,显卡是租的4090 24G,官网:https://ppio.com,使用模版:image.ppinfra.com/prod-gpucloudpublic/cuda:12.8.1-ubuntu22.04-devel
所有模型文件均使用git进行下载,如:
git lfs install ; git clone https://www.modelscope.cn/qwen/Qwen3.5-9B.git
请提前准备好模型文件,把上一步的后缀改成下面的路径使用git下载即可
qwen/Qwen3.5-9B
BAAI/bge-m3
BAAI/bge-reranker-v2-m3
一、安装conda
下载
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
安装
安装过程中注意:
一路回车
看到 Do you accept the license? 输入 yes
安装路径默认即可(或 /root/miniconda3)
bash Miniconda3-latest-Linux-x86_64.sh
安装完成后执行:
source ~/.bashrc
二、创建虚拟环境
conda create -n vllm0191 -y python=3.10
conda activate vllm0191
三、安装依赖
pip install torch==2.3.1 torchvision torchaudio -i https://mirrors.cloud.tencent.com/pypi/simple
安装vllm0.19.1版本
pip install \
vllm==0.19.1 \
fastapi==0.136.3 \
prometheus-fastapi-instrumentator==7.1.0 \
-i https://mirrors.cloud.tencent.com/pypi/simple
注:必须安装fastapi版本,否则存在兼容bug,issiue:https://github.com/trallnag/prometheus-fastapi-instrumentator/issues/370?utm_source=chatgpt.com
四、启动模型
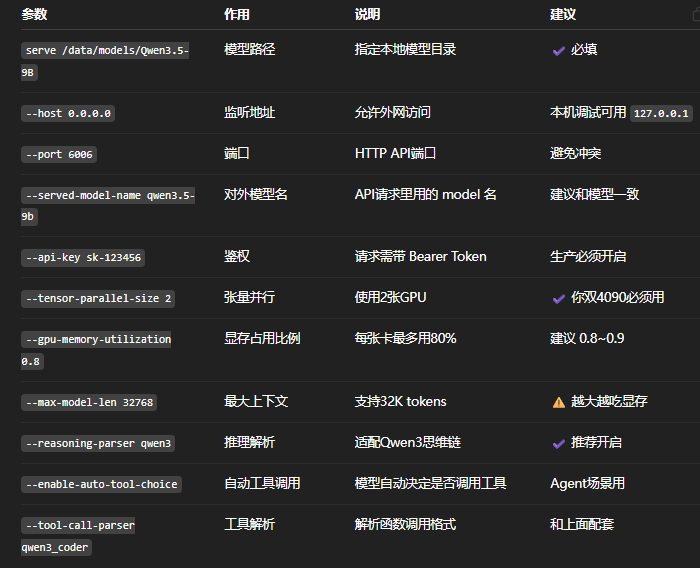
vllm serve /data/models/Qwen3.5-9B \
--host 0.0.0.0 \
--port 6006 \
--served-model-name qwen3.5-9b \
--api-key sk-123456 \
--tensor-parallel-size 2 \
--gpu-memory-utilization 0.8 \
--max-model-len 32768 \
--reasoning-parser qwen3 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder
五、验证模型
普通请求
(base) root@454ac432f1ddc4fd:~# curl http://localhost:6006/v1/chat/completions -H "Content-Type: application/json" -H "Authorization: Bearer sk-123456" -d '{
"model": "qwen3.5-9b",
"messages": [
{
"role": "user",
"content": "今天天气不错"
}
]
}' | jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 5901 100 5765 100 136 443 10 0:00:13 0:00:12 0:00:01 1204
{
"id": "chatcmpl-83e0b92b334a3970",
"object": "chat.completion",
"created": 1776739539,
"model": "qwen3.5-9b",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "\n\n是啊,天气好确实让人心情愉悦!🌤️\n\n这么好的天,你打算怎么过?是打算出去走走、晒晒太阳,还是找个舒服的地方悠闲地休息一下?☕️",
"refusal": null,
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": [],
"reasoning": "Thinking Process:\n\n1. **Analyze the Input:**\n * Input: \"今天天气不错\" (Today's weather is nice).\n * Language: Chinese.\n * Tone: Casual, conversational, positive.\n * Intent: The user is sharing an observation about the weather, possibly looking for a response, agreement, or conversation starter.\n\n2. **Determine the Appropriate Response:**\n * Acknowledge the statement (validate their feeling).\n * Express agreement or shared sentiment (if possible, though as an AI, I don't experience weather personally, I can simulate the sentiment).\n * Expand on the topic (ask about their plans, suggest activities suitable for nice weather, etc.).\n * Keep the tone friendly and engaging.\n\n3. **Drafting Potential Responses:**\n * *Option 1 (Simple agreement):* 是啊,今天确实很好。(Yes, it is quite good indeed.) - A bit dry.\n * *Option 2 (Detailed):* 是啊,阳光明媚,适合出去走走。(Yes, sunny and bright, suitable for a walk.) - Better.\n * *Option 3 (Engaging):* 好极了!你打算怎么度过今天这么好的天气?(Excellent! How do you plan to spend such a nice day?) - Good for conversation.\n * *Option 4 (Poetic/Mood):* 这么好的天气,心情都会变好。(Such good weather, makes people's mood better.) - Relatable.\n\n4. **Selecting and Refining the Best Response:**\n * Combine agreement with an invitation to chat about plans.\n * Add an emoji to match the friendly tone.\n * Acknowledge the weather without pretending to be human (though subtle human-like empathy is okay).\n\n *Refined Draft:* 是啊,这么好的天气确实让人心情愉悦!🌤️ 你打算去外面走走,还是在家悠闲地享受一下?如果有计划的话,记得保护好紫外线哦~ (Yes, such good weather indeed makes people happy! ☀️ Are you planning to go out for a walk, or enjoy the day leisurely at home? If you have plans, remember to protect against UV rays~)\n\n5. **Final Polish (Short & Sweet):**\n * Keep it natural.\n * \"是啊,阳光充足/空气好/风很舒服...\" (Depends, but generic \"can talk about it\").\n * Let's go with: \"是啊,听起来很舒服!趁着天气好,有没有什么计划想出去走走或者做点喜欢的事?☀️😄\" (Yes, sounds comfortable! Taking advantage of the good weather, any plans to go out or do something you like?)\n\n6. **Final Decision:**\n * Acknowledge the nice weather.\n * Suggest activities.\n * Use emojis.\n\n *Selected Response:* 是啊,天气好确实能让人心情变好!🌤️ 那你今天有什么安排吗?是打算出去溜溜达达,还是就在家里悠闲地享受一下好时光?☕️\n\n7. **Output Generation** (Translate thought to final output).\n\n *Self-Correction during output generation:* Keep it concise but warm.\n\n *Final Choice:* 是啊,天气好确实让人心情变好!🌤️ 那你今天有什么安排吗?是打算出去走走,还是找点吃的,悠闲地享受一下好时光?☕️有空 Sunga 还可以多晒晒太阳,心情更棒~ (Wait, \"Sunga\" is wrong. Let's remove that typo.)\n\n *Revised Final Choice:* 是啊,天气好确实让人心情变好!🌤️ 那你今天有什么安排吗?是打算出去走走,还是找点好吃的,悠闲地享受一下好时光?☕️ 晒晒太阳,心情也会更棒的~\n\n *Wait, keep it simpler.*\n \"是啊,真不错!这么好的天气,适合出去逛逛、晒晒太阳,或者找个舒服的地方坐坐。你打算怎么过?😊\"\n\n *Let's pick a balanced one.*\n \"是啊,阳光正好,微风不燥!🌤️ 这么好的天气,有没有什么特别的计划?比如去公园走走,或者约朋友喝杯咖啡?☕️\"\n\n *Actually, simplest is often best.*\n \"是啊,听起来很舒服!☀️ 这么好的天气,你打算怎么过?是出去走走,还是宅家休息呀?\"\n\n *Let's add a bit more warmth.*\n \"是啊,天气好确实能治愈心情~ 🌤️ 你那边有太阳吗?有没有计划出门溜达溜达,或者享受一下午后时光?☕️\"\n\n *Wait, I don't know where they are.*\n \"是啊,天气好确实让人心情愉悦!🌤️ 那你今天有什么安排吗?是打算出去走走,还是在家享受悠闲时光?☀️\"\n\n *Okay, final version.*\n 是啊,天气好确实让人心情变好!🌤️\n 那你今天有什么安排吗?是打算出去逛逛,还是找个舒服的地方发发呆?\n 有空的话,记得多喝水,晒晒太阳呀~ ☕️\n\n *Let's make it concise.*\n 是啊,真舒服!🌤️ 这么好的天气,你打算怎么过?是出去走走,还是找个惬意的小角落休息一下?☕️\n (Yes, so comfortable! 🌤️ So good weather, what do you plan to do? Go out or find a cozy corner to rest? ☕️)\n\n *Okay, let's output.*\n"
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null,
"token_ids": null
}
],
"service_tier": null,
"system_fingerprint": null,
"usage": {
"prompt_tokens": 13,
"total_tokens": 1289,
"completion_tokens": 1276,
"prompt_tokens_details": null
},
"prompt_logprobs": null,
"prompt_token_ids": null,
"kv_transfer_params": null
}
工具调用请求
(base) root@454ac432f1ddc4fd:~# curl http://localhost:6006/v1/chat/completions -H "Content-Type: application/json" -H "Authorization: Bearer sk-123456" -d '{
"model": "qwen3.5-9b",
"messages": [
{
"role": "user",
"content": "帮我查一下北京天气"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取某个城市的天气",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称"
}
},
"required": ["city"]
}
}
}
]
}' | jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1405 100 809 100 596 930 685 --:--:-- --:--:-- --:--:-- 1614
{
"id": "chatcmpl-81fc69f0ade16d78",
"object": "chat.completion",
"created": 1776739484,
"model": "qwen3.5-9b",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": null,
"refusal": null,
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": [
{
"id": "chatcmpl-tool-b9ca51b5fa44c462",
"type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"city\": \"北京\"}"
}
}
],
"reasoning": "用户想查询北京的天气,我需要使用get_weather工具,参数city需要设置为\"北京\"。\n"
},
"logprobs": null,
"finish_reason": "tool_calls",
"stop_reason": null,
"token_ids": null
}
],
"service_tier": null,
"system_fingerprint": null,
"usage": {
"prompt_tokens": 278,
"total_tokens": 327,
"completion_tokens": 49,
"prompt_tokens_details": null
},
"prompt_logprobs": null,
"prompt_token_ids": null,
"kv_transfer_params": null
}
curl -X POST 'http://127.0.0.1:6007/v1/rerank' -H 'Content-Type: application/json' -H 'Authorization: Bearer sk-123456' -d '{
"model":"bge-reranker-v2-m3",
"query":"什么是大模型",
"documents":[
"大模型是一种基于Transformer的深度学习模型",
"今天天气很好",
"GPT和Qwen属于大语言模型"
]
}'
六、部署embeding模型与 rerank模型
模型部署
使用1024维度的bge-m3对中英文都非常友好
bge‑reranker‑v2‑m3:二代模型,基于 bge‑m3 基座,在 BEIR、MIRACL、CMTEB 等权威榜单全面优于 large,多语言与中英场景都更强。
import argparse
from typing import List, Dict
import torch
from fastapi import FastAPI, HTTPException
from fastapi.responses import PlainTextResponse
from pydantic import BaseModel
from transformers import AutoTokenizer, AutoModel, AutoModelForSequenceClassification
import uvicorn
# ---------------------------
# CLI 参数
# ---------------------------
parser = argparse.ArgumentParser()
parser.add_argument("--embed_model_path", type=str, default="/data/models/bge-m3")
parser.add_argument("--rerank_model_path", type=str, default="/data/models/bge-reranker-v2-m3")
parser.add_argument("--host", type=str, default="0.0.0.0")
parser.add_argument("--port", type=int, default=6007)
parser.add_argument("--batch_size", type=int, default=32)
parser.add_argument("--max_len", type=int, default=512)
args = parser.parse_args()
SUPPORT_STATUS = 1
# ---------------------------
# device
# ---------------------------
device = "cuda" if torch.cuda.is_available() else "cpu"
dtype = torch.float16 if device == "cuda" else torch.float32
# ---------------------------
# load embedding model
# ---------------------------
print(f"[启动] 加载 embedding: {args.embed_model_path}")
embed_tokenizer = AutoTokenizer.from_pretrained(args.embed_model_path)
embed_model = AutoModel.from_pretrained(
args.embed_model_path,
torch_dtype=dtype
).to(device)
embed_model.eval()
# ---------------------------
# load reranker model
# ---------------------------
print(f"[启动] 加载 reranker: {args.rerank_model_path}")
rerank_tokenizer = AutoTokenizer.from_pretrained(args.rerank_model_path)
rerank_model = AutoModelForSequenceClassification.from_pretrained(
args.rerank_model_path,
torch_dtype=dtype
).to(device)
rerank_model.eval()
print(f"[启动] 模型加载完成,设备: {device}")
# ---------------------------
# FastAPI
# ---------------------------
app = FastAPI()
class EmbedRequest(BaseModel):
texts: List[str]
class RerankRequest(BaseModel):
query: str
docs: List[str]
# ---------------------------
# embedding
# ---------------------------
@torch.no_grad()
def encode_dense(texts: List[str]) -> List[List[float]]:
result = []
for i in range(0, len(texts), args.batch_size):
batch = texts[i:i + args.batch_size]
inputs = embed_tokenizer(
batch,
padding=True,
truncation=True,
max_length=args.max_len,
return_tensors="pt"
).to(device)
outputs = embed_model(**inputs)
embeddings = outputs.last_hidden_state[:, 0]
embeddings = torch.nn.functional.normalize(embeddings, p=2, dim=1)
result.extend(embeddings.cpu().float().tolist())
return result
# ---------------------------
# rerank
# ---------------------------
@torch.no_grad()
def rerank(query: str, docs: List[str]):
pairs = [[query, doc] for doc in docs]
scores = []
for i in range(0, len(pairs), args.batch_size):
batch = pairs[i:i + args.batch_size]
inputs = rerank_tokenizer(
batch,
padding=True,
truncation=True,
max_length=args.max_len,
return_tensors="pt"
).to(device)
outputs = rerank_model(**inputs)
logits = outputs.logits.squeeze(-1)
scores.extend(logits.cpu().float().tolist())
# 排序
ranked = sorted(
zip(docs, scores),
key=lambda x: x[1],
reverse=True
)
return [
{"doc": doc, "score": float(score)}
for doc, score in ranked
]
# ---------------------------
# API
# ---------------------------
@app.post("/embedding")
def embedding(req: EmbedRequest):
if not req.texts:
return {"dense": []}
try:
dense = encode_dense(req.texts)
return {"dense": dense}
except Exception as e:
raise HTTPException(500, str(e))
@app.post("/rerank")
def rerank_api(req: RerankRequest):
if not req.docs:
return []
try:
return rerank(req.query, req.docs)
except Exception as e:
raise HTTPException(500, str(e))
@app.get("/support_status", response_class=PlainTextResponse)
def support_status():
return str(SUPPORT_STATUS)
@app.get("/health")
def health():
return {
"status": "ok",
"device": device
}
# ---------------------------
# main
# ---------------------------
if __name__ == "__main__":
uvicorn.run(
app,
host=args.host,
port=args.port,
workers=1
)
模型运行
python embedding_rerank.py --rerank_model_path /data/models/bge-reranker-v2-m3 --embed_model_path /data/models/bge-m3 \
--host 0.0.0.0 \
--port 6007 \
--batch_size 32 \
--max_len 512
模型测试
(base) root@454ac432f1ddc4fd:/data/models# curl -X POST http://localhost:6007/rerank -H "Content-Type: application/json" -d '{
"query": "你在做什么",
"docs": ["大模型是AI模型", "今天天气很好","我在吃饭"]
}' | jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 254 100 143 100 111 5362 4162 --:--:-- --:--:-- --:--:-- 9769
[
{
"doc": "我在吃饭",
"score": -1.42578125
},
{
"doc": "大模型是AI模型",
"score": -7.6328125
},
{
"doc": "今天天气很好",
"score": -10.9296875
}
]
(base) root@454ac432f1ddc4fd:/data/models# curl -X POST http://localhost:6007/rerank \
-H "Content-Type: application/json" \
-d '{
"query": "今天天气怎么样",
"docs": ["大模型是AI模型", "今天天气很好","我在吃饭"]
}' | jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 259 100 142 100 117 5309 4374 --:--:-- --:--:-- --:--:-- 9961
[
{
"doc": "今天天气很好",
"score": 3.26171875
},
{
"doc": "我在吃饭",
"score": -10.734375
},
{
"doc": "大模型是AI模型",
"score": -11.0390625
}
]