
本文介绍了如何在消费级显卡上使用SGLang框架推理千问最新发布Qwen3.5-9B版本的小模型,无坑版本,可直接运行,显卡是autodl租的,官网:https://autodl.com
个人感觉qwen3.5还是使用SGLang更好一点,使用vllm要是用beta版本,不是很稳,sglang要使用0.5.10版本,不然会对qwen3.5有bug
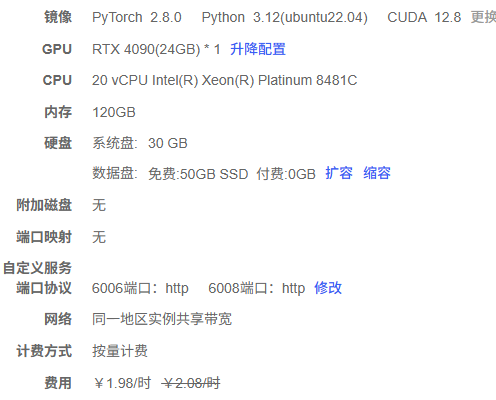
配置参数如下:
创建虚拟环境
使用配置文件创建,可以尽可能的避免陷入版本陷阱
双保险恢复
conda env create -f env.yml
pip install -r requirements.txt
创建如下两个配置文件,使用上面的命令进行恢复
env.yml
name: sglang510
channels:
- defaults
dependencies:
- _libgcc_mutex=0.1=main
- _openmp_mutex=5.1=1_gnu
- bzip2=1.0.8=h5eee18b_6
- ca-certificates=2026.3.19=h06a4308_0
- ld_impl_linux-64=2.44=h9e0c5a2_3
- libexpat=2.7.5=h7354ed3_0
- libffi=3.4.4=h6a678d5_1
- libgcc=15.2.0=h69a1729_7
- libgcc-ng=15.2.0=h166f726_7
- libgomp=15.2.0=h4751f2c_7
- libnsl=2.0.0=h5eee18b_0
- libstdcxx=15.2.0=h39759b7_7
- libstdcxx-ng=15.2.0=hc03a8fd_7
- libuuid=1.41.5=h5eee18b_0
- libxcb=1.17.0=h9b100fa_0
- libzlib=1.3.1=hb25bd0a_0
- ncurses=6.5=h7934f7d_0
- openssl=3.5.6=h1b28b03_0
- packaging=26.0=py310h06a4308_0
- pip=26.0.1=pyhc872135_1
- pthread-stubs=0.3=h0ce48e5_1
- python=3.10.20=h741d88c_0
- readline=8.3=hc2a1206_0
- setuptools=82.0.1=py310h06a4308_0
- sqlite=3.51.2=h3e8d24a_0
- tk=8.6.15=h54e0aa7_0
- wheel=0.46.3=py310h06a4308_0
- xorg-libx11=1.8.12=h9b100fa_1
- xorg-libxau=1.0.12=h9b100fa_0
- xorg-libxdmcp=1.1.5=h9b100fa_0
- xorg-xorgproto=2024.1=h5eee18b_1
- xz=5.8.2=h448239c_0
- zlib=1.3.1=hb25bd0a_0
- pip:
- aiohappyeyeballs==2.6.1
- aiohttp==3.13.5
- aiosignal==1.4.0
- airportsdata==20260315
- annotated-doc==0.0.4
- annotated-types==0.7.0
- anthropic==0.96.0
- anyio==4.13.0
- apache-tvm-ffi==0.1.10
- asttokens==3.0.1
- async-timeout==5.0.1
- attrs==26.1.0
- blobfile==3.0.0
- build==1.4.3
- certifi==2026.2.25
- cffi==2.0.0
- charset-normalizer==3.4.7
- click==8.3.2
- cloudpickle==3.1.2
- compressed-tensors==0.15.0.1
- cuda-bindings==12.9.6
- cuda-pathfinder==1.5.3
- cuda-python==12.9.0
- cuda-tile==1.2.0
- datasets==2.14.4
- decorator==5.2.1
- decord2==3.3.0
- dill==0.3.7
- diskcache==5.6.3
- distro==1.9.0
- docstring-parser==0.18.0
- einops==0.8.2
- exceptiongroup==1.3.1
- executing==2.2.1
- fastapi==0.136.0
- filelock==3.28.0
- flashinfer-python==0.6.7.post3
- frozenlist==1.8.0
- fsspec==2026.3.0
- gguf==0.18.0
- grpcio==1.80.0
- grpcio-health-checking==1.80.0
- grpcio-reflection==1.80.0
- h11==0.16.0
- hf-transfer==0.1.9
- hf-xet==1.4.3
- httpcore==1.0.9
- httpx==0.28.1
- huggingface-hub==0.36.2
- idna==3.11
- interegular==0.3.3
- ipython==8.39.0
- jedi==0.19.2
- jinja2==3.1.6
- jiter==0.14.0
- jsonschema==4.26.0
- jsonschema-specifications==2025.9.1
- lark==1.3.1
- llguidance==0.7.30
- loguru==0.7.3
- lxml==6.0.4
- markupsafe==3.0.3
- matplotlib-inline==0.2.1
- modelscope==1.35.4
- mpmath==1.3.0
- msgspec==0.21.1
- multidict==6.7.1
- multiprocess==0.70.15
- nest-asyncio==1.6.0
- networkx==3.4.2
- ninja==1.13.0
- numpy==2.2.6
- nvidia-cublas-cu12==12.8.4.1
- nvidia-cuda-cupti-cu12==12.8.90
- nvidia-cuda-nvrtc-cu12==12.8.93
- nvidia-cuda-runtime-cu12==12.8.90
- nvidia-cudnn-cu12==9.10.2.21
- nvidia-cudnn-frontend==1.22.1
- nvidia-cufft-cu12==11.3.3.83
- nvidia-cufile-cu12==1.13.1.3
- nvidia-curand-cu12==10.3.9.90
- nvidia-cusolver-cu12==11.7.3.90
- nvidia-cusparse-cu12==12.5.8.93
- nvidia-cusparselt-cu12==0.7.1
- nvidia-cutlass-dsl==4.3.5
- nvidia-ml-py==13.595.45
- nvidia-nccl-cu12==2.27.5
- nvidia-nvjitlink-cu12==12.8.93
- nvidia-nvshmem-cu12==3.3.20
- nvidia-nvtx-cu12==12.8.90
- openai==2.6.1
- openai-harmony==0.0.4
- orjson==3.11.8
- outlines==0.1.11
- outlines-core==0.1.26
- pandas==2.3.3
- parso==0.8.6
- partial-json-parser==0.2.1.1.post7
- pexpect==4.9.0
- pillow==12.2.0
- prometheus-client==0.25.0
- prompt-toolkit==3.0.52
- propcache==0.4.1
- protobuf==6.33.6
- psutil==7.2.2
- ptyprocess==0.7.0
- pure-eval==0.2.3
- py-spy==0.4.1
- pyarrow==23.0.1
- pybase64==1.4.3
- pycountry==26.2.16
- pycparser==3.0
- pycryptodomex==3.23.0
- pydantic==2.13.1
- pydantic-core==2.46.1
- pygments==2.20.0
- pyproject-hooks==1.2.0
- python-dateutil==2.9.0.post0
- python-multipart==0.0.26
- pytz==2026.1.post1
- pyyaml==6.0.3
- pyzmq==27.1.0
- quack-kernels==0.2.4
- referencing==0.37.0
- regex==2026.4.4
- requests==2.33.1
- rpds-py==0.30.0
- safetensors==0.7.0
- scipy==1.15.3
- sentencepiece==0.2.1
- setproctitle==1.3.7
- sgl-kernel==0.3.21
- sglang==0.5.10.post1
- sglang-kernel==0.4.1
- six==1.17.0
- smg-grpc-proto==0.4.6
- sniffio==1.3.1
- soundfile==0.13.1
- stack-data==0.6.3
- starlette==1.0.0
- sympy==1.14.0
- tabulate==0.10.0
- tiktoken==0.12.0
- timm==1.0.16
- tokenizers==0.22.2
- tomli==2.4.1
- torch==2.9.1
- torch-c-dlpack-ext==0.1.5
- torch-memory-saver==0.0.9
- torchao==0.9.0
- torchaudio==2.9.1
- torchcodec==0.8.0
- torchvision==0.24.1
- tqdm==4.67.3
- traitlets==5.14.3
- transformers==4.57.1
- triton==3.5.1
- typing-extensions==4.15.0
- typing-inspection==0.4.2
- tzdata==2026.1
- urllib3==2.6.3
- uv==0.11.7
- uvicorn==0.44.0
- uvloop==0.22.1
- wcwidth==0.6.0
- xgrammar==0.1.27
- xxhash==3.6.0
- yarl==1.23.0
requirements.txt
aiohappyeyeballs==2.6.1
aiohttp==3.13.5
aiosignal==1.4.0
airportsdata==20260315
annotated-doc==0.0.4
annotated-types==0.7.0
anthropic==0.96.0
anyio==4.13.0
apache-tvm-ffi==0.1.10
asttokens==3.0.1
async-timeout==5.0.1
attrs==26.1.0
blobfile==3.0.0
build==1.4.3
certifi==2026.2.25
cffi==2.0.0
charset-normalizer==3.4.7
click==8.3.2
cloudpickle==3.1.2
compressed-tensors==0.15.0.1
cuda-bindings==12.9.6
cuda-pathfinder==1.5.3
cuda-python==12.9.0
cuda-tile==1.2.0
datasets==2.14.4
decorator==5.2.1
decord2==3.3.0
dill==0.3.7
diskcache==5.6.3
distro==1.9.0
docstring_parser==0.18.0
einops==0.8.2
exceptiongroup==1.3.1
executing==2.2.1
fastapi==0.136.0
filelock==3.28.0
flashinfer-python==0.6.7.post3
frozenlist==1.8.0
fsspec==2026.3.0
gguf==0.18.0
grpcio==1.80.0
grpcio-health-checking==1.80.0
grpcio-reflection==1.80.0
h11==0.16.0
hf-xet==1.4.3
hf_transfer==0.1.9
httpcore==1.0.9
httpx==0.28.1
huggingface_hub==0.36.2
idna==3.11
interegular==0.3.3
ipython==8.39.0
jedi==0.19.2
Jinja2==3.1.6
jiter==0.14.0
jsonschema==4.26.0
jsonschema-specifications==2025.9.1
lark==1.3.1
llguidance==0.7.30
loguru==0.7.3
lxml==6.0.4
MarkupSafe==3.0.3
matplotlib-inline==0.2.1
modelscope==1.35.4
mpmath==1.3.0
msgspec==0.21.1
multidict==6.7.1
multiprocess==0.70.15
nest-asyncio==1.6.0
networkx==3.4.2
ninja==1.13.0
numpy==2.2.6
nvidia-cublas-cu12==12.8.4.1
nvidia-cuda-cupti-cu12==12.8.90
nvidia-cuda-nvrtc-cu12==12.8.93
nvidia-cuda-runtime-cu12==12.8.90
nvidia-cudnn-cu12==9.10.2.21
nvidia-cudnn-frontend==1.22.1
nvidia-cufft-cu12==11.3.3.83
nvidia-cufile-cu12==1.13.1.3
nvidia-curand-cu12==10.3.9.90
nvidia-cusolver-cu12==11.7.3.90
nvidia-cusparse-cu12==12.5.8.93
nvidia-cusparselt-cu12==0.7.1
nvidia-cutlass-dsl==4.3.5
nvidia-ml-py==13.595.45
nvidia-nccl-cu12==2.27.5
nvidia-nvjitlink-cu12==12.8.93
nvidia-nvshmem-cu12==3.3.20
nvidia-nvtx-cu12==12.8.90
openai==2.6.1
openai-harmony==0.0.4
orjson==3.11.8
outlines==0.1.11
outlines_core==0.1.26
packaging==26.0
pandas==2.3.3
parso==0.8.6
partial-json-parser==0.2.1.1.post7
pexpect==4.9.0
pillow==12.2.0
prometheus_client==0.25.0
prompt_toolkit==3.0.52
propcache==0.4.1
protobuf==6.33.6
psutil==7.2.2
ptyprocess==0.7.0
pure_eval==0.2.3
py-spy==0.4.1
pyarrow==23.0.1
pybase64==1.4.3
pycountry==26.2.16
pycparser==3.0
pycryptodomex==3.23.0
pydantic==2.13.1
pydantic_core==2.46.1
Pygments==2.20.0
pyproject_hooks==1.2.0
python-dateutil==2.9.0.post0
python-multipart==0.0.26
pytz==2026.1.post1
PyYAML==6.0.3
pyzmq==27.1.0
quack-kernels==0.2.4
referencing==0.37.0
regex==2026.4.4
requests==2.33.1
rpds-py==0.30.0
safetensors==0.7.0
scipy==1.15.3
sentencepiece==0.2.1
setproctitle==1.3.7
sgl-kernel==0.3.21
sglang==0.5.10.post1
sglang-kernel==0.4.1
six==1.17.0
smg-grpc-proto==0.4.6
sniffio==1.3.1
soundfile==0.13.1
stack-data==0.6.3
starlette==1.0.0
sympy==1.14.0
tabulate==0.10.0
tiktoken==0.12.0
timm==1.0.16
tokenizers==0.22.2
tomli==2.4.1
torch==2.9.1
torch_c_dlpack_ext==0.1.5
torch_memory_saver==0.0.9
torchao==0.9.0
torchaudio==2.9.1
torchcodec==0.8.0
torchvision==0.24.1
tqdm==4.67.3
traitlets==5.14.3
transformers==4.57.1
triton==3.5.1
typing-inspection==0.4.2
typing_extensions==4.15.0
tzdata==2026.1
urllib3==2.6.3
uv==0.11.7
uvicorn==0.44.0
uvloop==0.22.1
wcwidth==0.6.0
xgrammar==0.1.27
xxhash==3.6.0
yarl==1.23.0
验证环境
python -c "import torch; import aiohttp; import sglang; print('OK')"
python -c "import torch; print(torch.cuda.is_available())"
开始运行
python -m sglang.launch_server \
--model-path /data/models/Qwen3.5-9B \
--port 6006 \
--tp-size 1 \
--mem-fraction-static 0.8 \
--context-length 32768 \
--reasoning-parser qwen3 \
--tool-call-parser qwen3_coder \
--api-key sk-123456 \
--served-model-name qwen3.5-9b

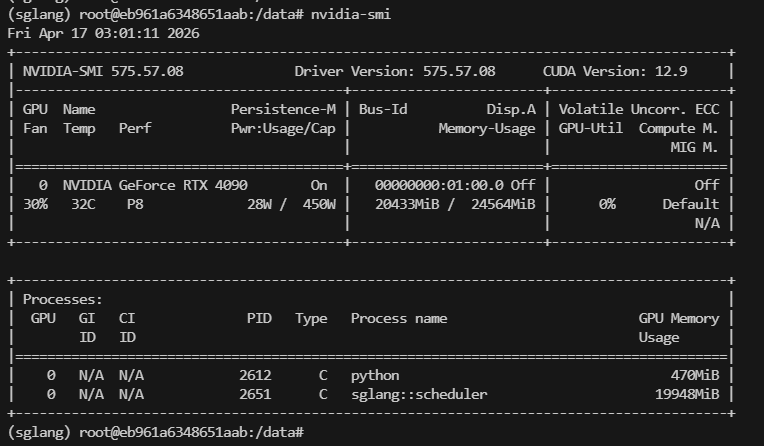
启动成功:

显存占用情况:20G左右
使用接口调用
(sglang) root@eb961a6348651aab:/data# curl http://localhost:6006/v1/chat/completions -H "Content-Type: application/json" -H "Authorization: Bearer sk-123456" -d '{
"model": "qwen3-8b",
"messages": [
{
"role": "user",
"content": "帮我查一下北京天气"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取某个城市的天气",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称"
}
},
"required": ["city"]
}
}
}
]
}' | jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1417 100 823 100 594 570 411 0:00:01 0:00:01 --:--:-- 981
{
"id": "69ea730cd12d4094a000679a1c5ba780",
"object": "chat.completion",
"created": 1776395481,
"model": "qwen3-8b",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": null,
"reasoning_content": "用户想要查询北京的天气,我需要使用get_weather工具来查询。这个工具需要一个city参数,用户已经提供了\"北京\"这个城市名称。\n\n我应该调用get_weather函数,参数city设置为\"北京\"。\n",
"tool_calls": [
{
"id": "call_c5d7b7789b364af08ecb7da3",
"index": 0,
"type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"city\": \"北京\"}"
}
}
]
},
"logprobs": null,
"finish_reason": "tool_calls",
"matched_stop": null
}
],
"usage": {
"prompt_tokens": 283,
"total_tokens": 356,
"completion_tokens": 73,
"prompt_tokens_details": null,
"reasoning_tokens": 0
},
"metadata": {
"weight_version": "default"
}
}
模型压测
使用压测脚本进行模拟用户使用,脚本如下
import asyncio
import aiohttp
import time
import random
import string
import argparse
from statistics import mean
# ================= Utils =================
def rand_prompt(length):
return "Explain briefly: " + "".join(
random.choices(string.ascii_lowercase, k=length)
)
def percentile(data, p):
if not data:
return 0
data = sorted(data)
k = int(len(data) * p)
return data[min(k, len(data) - 1)]
# ================= Request =================
async def call(session, config, results):
prompt = rand_prompt(config.input_len)
payload = {
"model": config.model,
"messages": [{"role": "user", "content": prompt}],
"max_tokens": config.output_len,
"temperature": 0.7,
}
headers = {
"Authorization": f"Bearer {config.api_key}",
"Content-Type": "application/json"
}
t0 = time.time()
async with session.post(config.url, json=payload, headers=headers) as resp:
data = await resp.json()
t1 = time.time()
latency = t1 - t0
usage = data.get("usage", {})
tokens = usage.get("completion_tokens", config.output_len)
tps = tokens / latency if latency > 0 else 0
results.append((latency, tps))
# ================= Worker =================
async def user_worker(session, config, results):
for _ in range(config.requests_per_user):
await call(session, config, results)
# ================= Main =================
async def run(config):
results = []
timeout = aiohttp.ClientTimeout(total=None)
connector = aiohttp.TCPConnector(limit=0)
async with aiohttp.ClientSession(timeout=timeout, connector=connector) as session:
tasks = [
asyncio.create_task(user_worker(session, config, results))
for _ in range(config.users)
]
start = time.time()
await asyncio.gather(*tasks)
total_time = time.time() - start
# ================= Analysis =================
latencies = [x[0] for x in results]
tps_list = [x[1] for x in results]
qps = len(results) / total_time if total_time > 0 else 0
print("\n===== OFFICE BENCH RESULT =====")
print(f"Users: {config.users}")
print(f"Requests: {len(results)}")
print(f"Total Time: {total_time:.2f}s")
print("\nLatency (seconds):")
print(f" Avg: {mean(latencies):.2f}")
print(f" P50: {percentile(latencies, 0.50):.2f}")
print(f" P95: {percentile(latencies, 0.95):.2f}")
print(f" P99: {percentile(latencies, 0.99):.2f}")
print("\nToken Speed (TPS):")
print(f" Avg: {mean(tps_list):.2f}")
print(f" Min: {min(tps_list):.2f}")
print(f" Max: {max(tps_list):.2f}")
print("\nThroughput:")
print(f" QPS: {qps:.2f}")
# ================= Args =================
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("--url", default="http://localhost:6006/v1/chat/completions")
parser.add_argument("--api-key", default="sk-123456")
parser.add_argument("--model", default="qwen3.5-9b")
parser.add_argument("--users", type=int, default=10)
parser.add_argument("--requests-per-user", type=int, default=5)
parser.add_argument("--input-len", type=int, default=30)
parser.add_argument("--output-len", type=int, default=128)
return parser.parse_args()
# ================= Entry =================
if __name__ == "__main__":
config = parse_args()
asyncio.run(run(config))
开始执行模拟使用
(sglang) root@eb961a6348651aab:/data# python office_load_test.py --url http://localhost:6006/v1/chat/completions --api-key sk-123456 --model qwen3.5-9b --users 10 --requests-per-user 5
===== OFFICE BENCH RESULT =====
Users: 10
Requests: 50
Total Time: 67.06s
Latency (seconds):
Avg: 12.34
P50: 13.40
P95: 13.42
P99: 13.47
Token Speed (TPS):
Avg: 11.93
Min: 9.50
Max: 46.49
Throughput:
QPS: 0.75
问题处理
报错:Error details from previous import attempts: - ImportError: libnuma.so.1: cannot open shared object file: No such file or directory - ModuleNotFoundError: No module named ‘common_ops’
原因:
系统缺少 NUMA 库
解决:
更新仓库源
cp /etc/apt/sources.list /etc/apt/sources.list.bak
cat > /etc/apt/sources.list <<EOF
deb http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
EOF
下载依赖包
apt-get update && apt-get install -y libnuma1
# 验证一下
ldconfig -p | grep libnuma
报错:
Current Environment: PyTorch 2.9.1+cu128 | CuDNN 9.10 Issue: There is a KNOWN BUG in PyTorch 2.9.1's nn.Conv3d implementation when used with CuDNN versions older than 9.15. This can cause SEVERE PERFORMANCE DEGRADATION and EXCESSIVE MEMORY USAGE. Reference: https://github.com/pytorch/pytorch/issues/168167
原因:
你当前环境:
PyTorch:2.9.1 + cu128
CuDNN:9.10(太低)
GPU:4090(OK)
👉 已知 bug:
PyTorch 2.9.1 + CuDNN < 9.15
👉 会导致:
推理巨慢
显存异常暴涨
所以 sglang 直接拒绝启动(强制保护)
解决:
pip install -U nvidia-cudnn-cu12==9.16.0.29
# 退出当前 shell 或重新激活
conda deactivate
conda activate sglang