
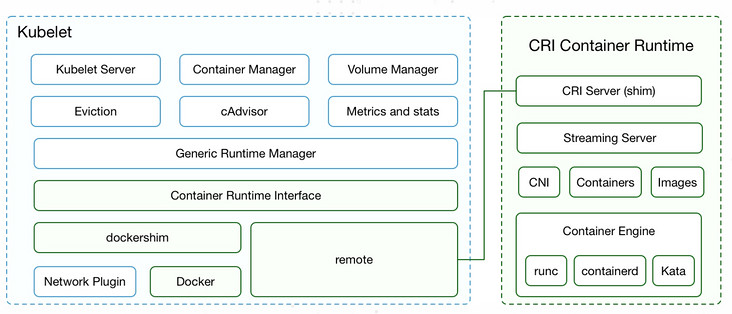
kubelet架构图
-
两种容器运行时的实现
- 一个是内置的 dockershim,实现了 docker 容器引擎的支持
- 一个就是外部的容器运行时,用来支持 runc、containerd、gvisor 等外部容器运行时
-
CRI接口分类
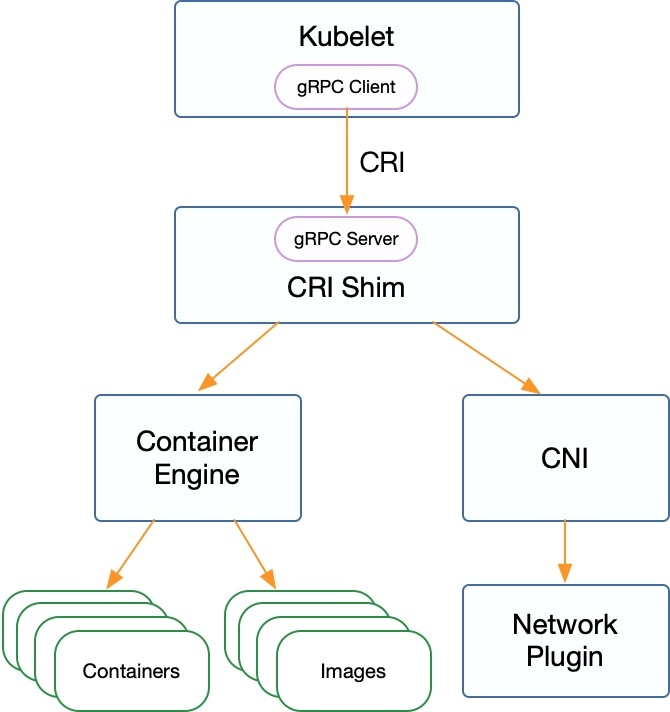
- 管理镜像的 ImageService 提供了 5 个接口
- 管理容器的RuntimeService 则提供了更多的接口
- Streaming API 用于客户端与容器进行交互
-
k8s中的容器运行时按照不同的功能就可以分为三个部分:
- 第一个是 Kubelet 中容器运行时的管理,它通过 CRI 管理容器和镜像
- 第二个是容器运行时接口,是 Kubelet 与外部容器运行时的通信接口
- 第三个是具体的容器运行时实现,包括 Kubelet 内置的 dockershim 以及外部的容器运行时(如 cri-o、cri-containerd、frakti等)
-
CRI Server: 这是 CRI gRPC server,监听在 unix socket 上面
-
Streaming Server: 提供 streaming API,包括 Exec、Attach、Port Forward
-
容器和镜像的管理:比如拉取镜像、创建和启动容器等
-
CNI 网络插件的支持: 用于给容器配置网络
-
容器引擎的管理: 比如支持 runc 、containerd 或者支持多个容器引擎
容器运行时的演进过程
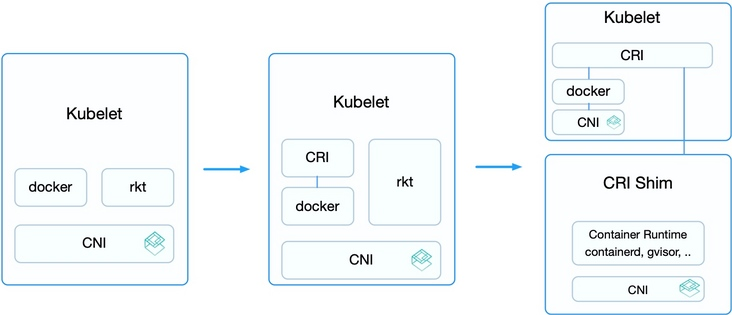
第一阶段:
- 在 Kubernetes v1.5 之前,Kubelet 内置了 Docker 和 rkt 的支持
- 并且通过 CNI 网络插件给它们配置容器网络
- 这个阶段的用户如果需要自定义运行时的功能是比较痛苦的,需要修改 Kubelet 的代码,并且很有可能这些修改无法推到上游社区
- 这样,还需要维护一个自己的 fork 分支,维护和升级都非常麻烦。
第二阶段:
- 不同用户实现的容器运行时各有所长,许多用户都希望Kubernetes支持更多的运行时
- 于是,从v1.5 开始增加了 CRI 接口,通过容器运行时的抽象层消除了这些障碍,使得无需修改 Kubelet 就可以支持运行多种容器运行时
- CRI 接口包括了一组 Protocol Buffer、gRPC API 、用于 streaming 接口的库以及用于调试和验证的一系列工具等
- 在此阶段,内置的 Docker 实现也逐步迁移到了 CRI 的接口之下
- 但此时 rkt 还未完全迁移,这是因为 rkt 迁移 CRI 的过程将在独立的 repository 完成,方便其维护和管理。
第三阶段:
- 从 v1.11 开始,Kubelet 内置的 rkt 代码删除,CNI 的实现迁移到 dockershim 之内
- 这样,除了 docker 之外,其他的容器运行时都通过 CRI 接入
- 外部的容器运行时一般称为 CRI Shim,它除了实现 CRI 接口外,也要负责为容器配置网络
- 一般推荐使用 CNI,因为这样可以支持社区内的众多网络插件,不过这不是必需的,网络插件只需要满足 Kubernetes 网络的基本假设即可,即 IP-per-Pod、所有 Pod 和 Node 都可以直接通过 IP 相互访问。
容器运行时接口(CRI)
-
容器运行时接口(CRI)是一个用来扩展容器运行时的接口
-
它基于 gPRC,用户不需要关心内部通信逻辑,而只需要实现定义的接口就可以,包括 RuntimeService 和 ImageService。
- RuntimeService负责管理Pod和容器的生命周期
- ImageService负责镜像的生命周期管理
-
除了 gRPC API,CRI 还包括用于实现 streaming server 的库(用于 Exec、Attach、PortForward 等接口)和 CRI Tools。
基于 CRI 接口的容器运行时通常称为 CRI shim
- 这是一个 gRPC Server,监听在本地的unix socket上
- 而kubelet作为gRPC的客户端来调用CRI接口
- 另外,外部容器运行时需要自己负责管理容器的网络,推荐使用CNI,这样跟Kubernetes的网络模型保持一致
CRI 的推出为容器社区带来了新的繁荣
-
cri-o、frakti、cri-containerd 等一些列的容器运行时为不同场景而生:
- cri-containerd——基于 containerd 的容器运行时
- cri-o——基于 OCI 的容器运行时
- frakti——基于虚拟化的容器运行时
-
而基于这些容器运行时,还可以轻易联结新型的容器引擎,比如可以通过 clear container、gVisor 等新的容器引擎配合 cri-o 或 cri-containerd 等轻易接入 Kubernetes,将 Kubernetes 的应用场景扩展到了传统 IaaS 才能实现的强隔离和多租户场景。
-
当使用CRI运行时,需要配置kubelet的–container-runtime参数为remote,并设置–container-runtime-endpoint为监听的unix socket位置(Windows上面为 tcp 端口)。
CRI 接口
- CRI 接口包括 RuntimeService 和 ImageService 两个服务,
- 这两个服务可以在一个 gRPC server 里面实现,当然也可以分开成两个独立服务
- 目前社区的很多运行时都是将其在一个 gRPC server 里面实现。

CRI接口分类
管理镜像的 ImageService 提供了 5 个接口
- 分别是查询镜像列表
- 拉取镜像到本地
- 查询镜像状态
- 删除本地镜像
- 查询镜像占用空间等
RuntimeService 则提供了更多的接口,按照功能可以划分为四组
PodSandbox 的管理接口
- PodSandbox 是对 Kubernete Pod 的抽象
- 用来给容器提供一个隔离的环境(比如挂载到相同的 cgroup 下面),并提供网络等共享的命名空间
- PodSandbox 通常对应到一个 Pause 容器或者一台虚拟机。
Container 的管理接口
- 在指定的 PodSandbox 中创建、启动、停止和删除容器。
Streaming API 接口
- 包括 Exec、Attach 和 PortForward 等三个和容器进行数据交互的接口
- 这三个接口返回的是运行时 Streaming Server 的 URL,而不是直接跟容器交互
状态接口
- 包括查询 API 版本和查询运行时状态。
Streaming API
作用
- Streaming API 用于客户端与容器进行交互,三个接口如下
- Exec
- PortForward
- Attach
适配
- Kubelet 内置的 docker 通过 nsenter、socat 等方法来支持这些特性
- 但它们不一定适用于其他的运行时,也不支持 Linux 之外的其他平台
- 因而,CRI 也显式定义了这些 API,并且要求容器运行时返回一个 streaming server 的 URL 以便 Kubelet 重定向 API Server 发送过来的流式请求。
容器运行时启动专门的流处理服务
- 这是因为所有容器的流式请求都会经过 Kubelet,这有可能会给节点的网络流量带来瓶颈
- 因而 CRI 要求容器运行时启动一个对应请求的单独的流服务器将地址返回给Kubelet
- Kubelet然后将这个信息再返回给Kubernetes API Server,它会打开直接与运行时提供的服务器相连的流连接,并通过它跟客户端连通。
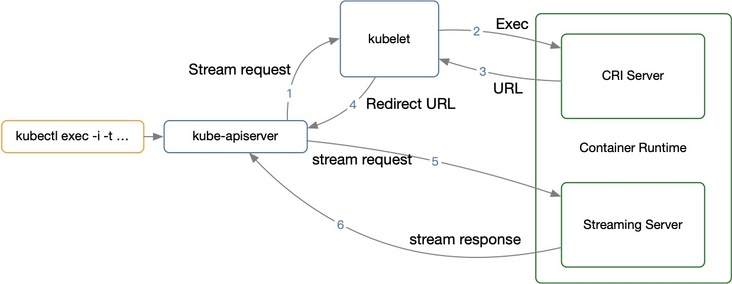
流处理交互过程
-
这样一个完整的 Exec 流程就如上图所示,分为多个阶段:
- 客户端 kubectl exec -i -t …
- kube-apiserver 向 Kubelet 发送流式请求 /exec/
- Kubelet 通过 CRI 接口向 CRI Shim 请求 Exec 的 URL
- CRI Shim 向 Kubelet 返回 Exec URL
- Kubelet 向 kube-apiserver 返回重定向的响应
- kube-apiserver 重定向流式请求到 Exec URL,接着就是 CRI Shim 内部的 Streaming Server 跟 kube-apiserver 进行数据交互,完成 Exec 的请求和响应
早期版本行为
- 在 v1.10 及更早版本中,容器运行时必需返回一个 API Server 可直接访问的 URL(通常跟 Kubelet 使用相同的监听地址)
- 而从 v1.11 开始,Kubelet 新增了–redirect-container-streaming选项(默认为 false),支持不转发而是代理 Streaming 请求,这样运行时可以返回一个 localhost 的 URL(当然也不再需要配置 TLS)。
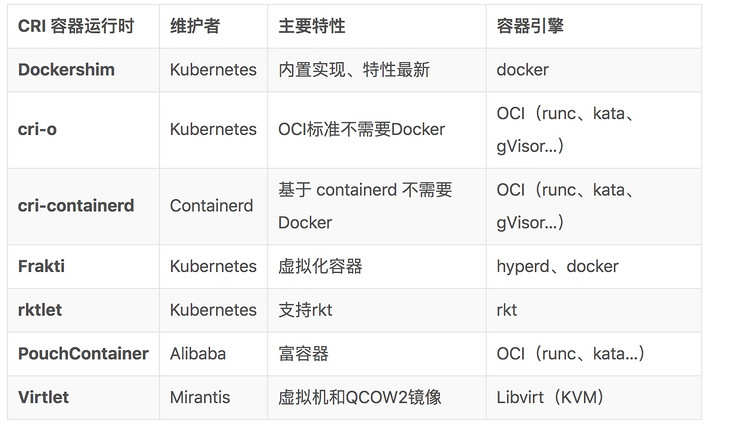
容器运行时分类
- 以下是几个常见容器运行时的例子,它们各有所长,并且也支持不同的容器引擎:
隔离性
-
在多租户场景下,强隔离(特别是虚拟化级别的隔离)是一个最基本的需求。
-
以前使用 Kubernetes 时,由于只支持Docker 容器,而它只提供了内核命名空间(namespace)的隔离,虽然也支持 SELinux、AppArmor 等基本的安全控制,但还是无法满足多租户的需求。所以曾经社区有人提出节点独占的方式实现租户隔离,即每个容器或租户独占一台虚拟机,资源的浪费是很明显的。
-
有了 CRI 之后,就可以接入 Kata Container、Clear Container 等基于虚拟化的容器引擎。这样通过虚拟化实现了容器的强隔离,不同租户的容器也可以运行在相同的 Node 上,大大提高了资源的利用率。
-
当然了,多租户不仅需要容器自身的强隔离,还需要众多其他的功能一起配合,比如
- 网络隔离,比如可以使用 CNI 构建新的网络插件,把不同租户的 Pod 接入到相互隔离的虚拟网络中。
- 资源管理,比如基于 CRD 构建租户 API 和租户控制器,管理租户和租户的资源。
- 认证、授权、配额管理等等也都可以在 Kubernetes API 之上构建。
工具
CRI Tools 是社区 Node 组针对 CRI 接口开发的辅助工具
-
它包括两个工具:crictl 和 critest。
-
crictl 是一个容器运行时命令行接口,它对系统和应用的排错来说是个很有用的工具
- 当使用 Docker 运行时,调试系统信息的时候我们可能使用 docker ps 和 docker inspect 等命令检查应用的进程情况
- 但是对于其他基于 CRI 的容器运行时来说,它们可能没有自己的命令行工具
- 或者即便有,它们的操作界面也不一定与 Kubernetes 中的概念一致
- 更不用说,很有很多的命令对 Kubernetes 没什么用,甚至会损害系统(比如 docker rename)
- 因而,我们推荐使用 crictl 作为 Docker CLI 的继任者,用于 Kubernetes 节点上 pod、容器以及镜像的除错工具。
-
crictl 提供了类似 Docker CLI 的使用体验, 并且支持所有 CRI 兼容的容器运行时
- 并且,crictl 提供了一个对 Kubernetes 来说更加友好的容器视角:它就是为 Kubernetes 而设计的,有不同的命令分别与Pod 和容器进行交互
- 例如 crictl pods 会列出 Pod 信息,而 crictl ps 只会列出应用容器的信息。
-
而 critest 则是一个容器运行时的验证测试工具,用于验证容器运行时是否符合 Kubelet CRI 的要求
- 除了验证测试,critest 还提供了 CRI 接口的性能测试,比如 critest -benchmark。
-
推荐将 critest 集成到容器运行时开发的 Devops 流程中,保证每个变更都不会破坏 CRI 的基本功能
- 另外,还可以选择将 critest 的测试结果与 Kubernetes Node E2E 的结果提交到 Sig-node 的 TestGrid,向社区和用户展示。
多容器运行时
- 多容器运行时用于不同的目的,比如使用虚拟化容器引擎式运行不可信应用和多租户应用
- 而使用 Docker 运行系统组件或者无法虚拟化的容器(比如需要 HostNetwork 的容器)。比如典型的用例为:
- Kata Containers/gVisor + runc
- Windows Process isolation + Hyper-V isolation containers
- 以前,多容器运行时通常以注解(Annotation)的形式支持,比如 cri-o、frakti 等都是这么支持了多容器运行时
- 但这一点也不优雅,并且也无法实现基于容器运行时来调度容器。因而,Kubernetes 在 v1.12 中将开始增加 RuntimeClass 这个新的 API 对象,用来支持多容器运行时。
GPU 支持
- Nvidia提供了k8s pod使用GPU的一整套解决方案。运行时方面,nvidia提供了特定的运行时,主要的功能是为了让container访问从node节点上分配的GPU资源。
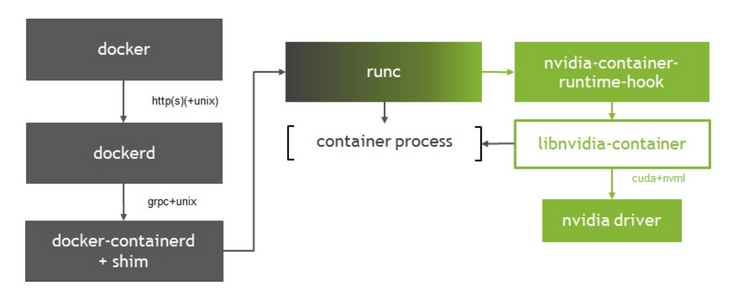
- 如上图所示,libnvidia-container被整合进docker的runc中
- 通过在runc的prestart hook 中调用nvidia-container-runtime-hook来控制GPU
- 启动容器时,prestart hook会校验环境变量GPU-enabled来校验该容器是否需要启用GPU,一旦确认需要启用,就调用nvidia定制的运行时来启动容器,从而为容器分配limit指定个数的GPU。
调度层面
- 在k8s的调度方面,nvidia基于k8s的device plugin来实现了kubelet层GPU资源的上报,通过在pod的spec中指定对应的limit来声明对GPU个数的申请情况
- 在spec中必须指定limit的值(且必须为整数),reqire的值要么不设置,要么等于limit的值。